
The Apache Hop community just released Apache Hop 2.2.0, the fifth (!!) and final release of 2022,
Why use Dataflow?
Google Cloud Dataflow is a Unified stream and batch data processing engine that is fully managed, fast, and cost-effective. Apache Hop offers native support for Dataflow via the Apache Beam integration. This means you can develop complex pipelines and immediately execute them hassle-free from the user interface.
This is great for development and testing but when this phase is finished you need to run your pipelines regularly and put them in production. There are multiple ways to put your pipelines in production when using Dataflow, Flex Templates are a simple approach to scheduling a pipeline.
What are Google Cloud Dataflow Templates?
Dataflow templates allow you to package a Dataflow pipeline for deployment. Anyone with the correct permissions can then use the template to deploy the packaged pipeline. We can leverage these Dataflow native abilities to schedule a pipeline that has been stored on Google Cloud Storage (GCS). Because of our focus on tight cloud integration, pipelines can be developed locally and stored in the cloud. This means you don't need to worry about compiling and packaging custom software for your pipelines to work in Google Cloud. All the needed parts to make this work are provided and you can start using it without writing a line of code.
Scheduling a pipeline walkthrough
Let's go through the steps needed to schedule a pipeline, the first step will be to select a pipeline that we will be scheduling. For this example, we will be using a simple pipeline that is included in the samples project. This pipeline can be found under samples/transforms/add-sequence-unique-id.hpl.
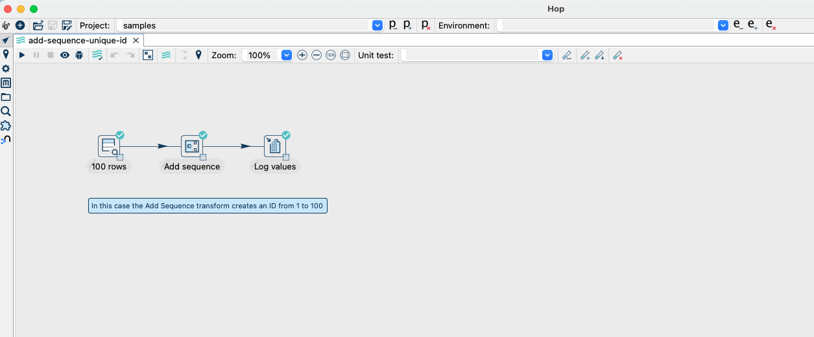
This sample pipeline will generate 100 rows, and add a sequence. Let's go through the steps required to schedule this pipeline.
Step 1: Upload the required files
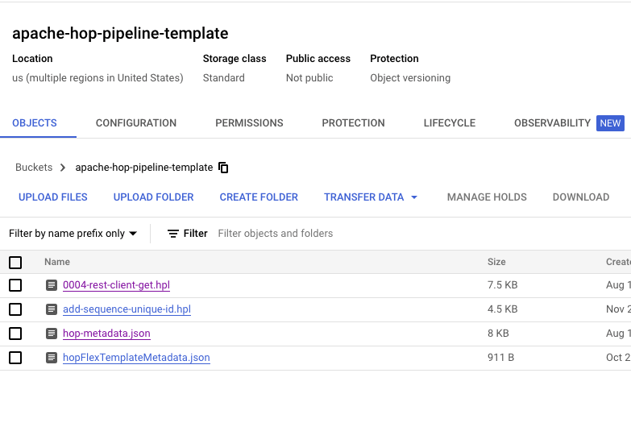
The first step is to prepare the files needed to execute the pipeline in the google cloud platform. For this we need to upload 3 files to a GCS bucket
- The pipeline (hpl) file
- This file contains the definition of your pipeline, all the transforms that need to be executed are described in this file
- Hop metadata export
- In Apache Hop, we have a clear split between the definition and the configuration. This metadata file contains all database configurations and environment variables. You can execute the same pipeline using multiple different configurations without the need to edit each individual file.
- To extract the current configuration press the Hop logo in the top left corner and select Export metadata to JSON
- Dataflow flex-template
- The flex template contains the definition used by Google Dataflow to configure the pipeline that has to be executed, it contains information such as the parameters needed to start the pipeline
- The template is a fixed file that can be found here
Upload these files using your preferred method. This can be the Google Cloud CLI or via the web console. The end result should be a bucket with everything to get started with the next step.
Step 2: Schedule the pipeline in Dataflow
The next step is creating a schedule in Dataflow. Go to the dataflow management console, and head over to the Pipelines section. Press the Create Data pipeline button.
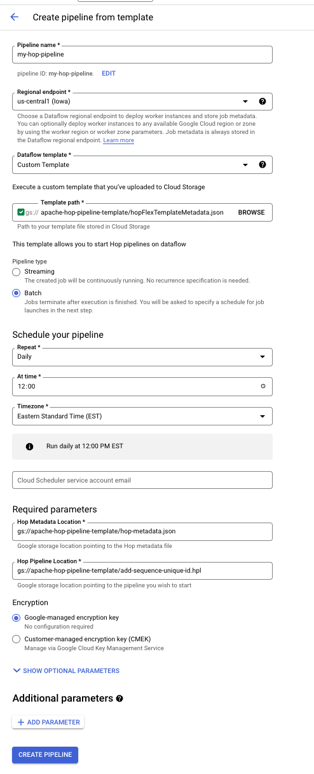
The following things have to be configured here to get your pipeline running:
- Pipeline Name
- Region
- Dataflow template
- This has to be Custom Template
- Template path
- This is the Dataflow flex-template provided from the previous step
- Pipeline type
- With this example it should be Batch
- Schedule
- Here you can define when the pipeline should run
- Required parameters
- The location of the exported hop metadata
- The pipeline you wish to run
Now we are ready to create and run our pipeline.
Step 3: Run your pipeline
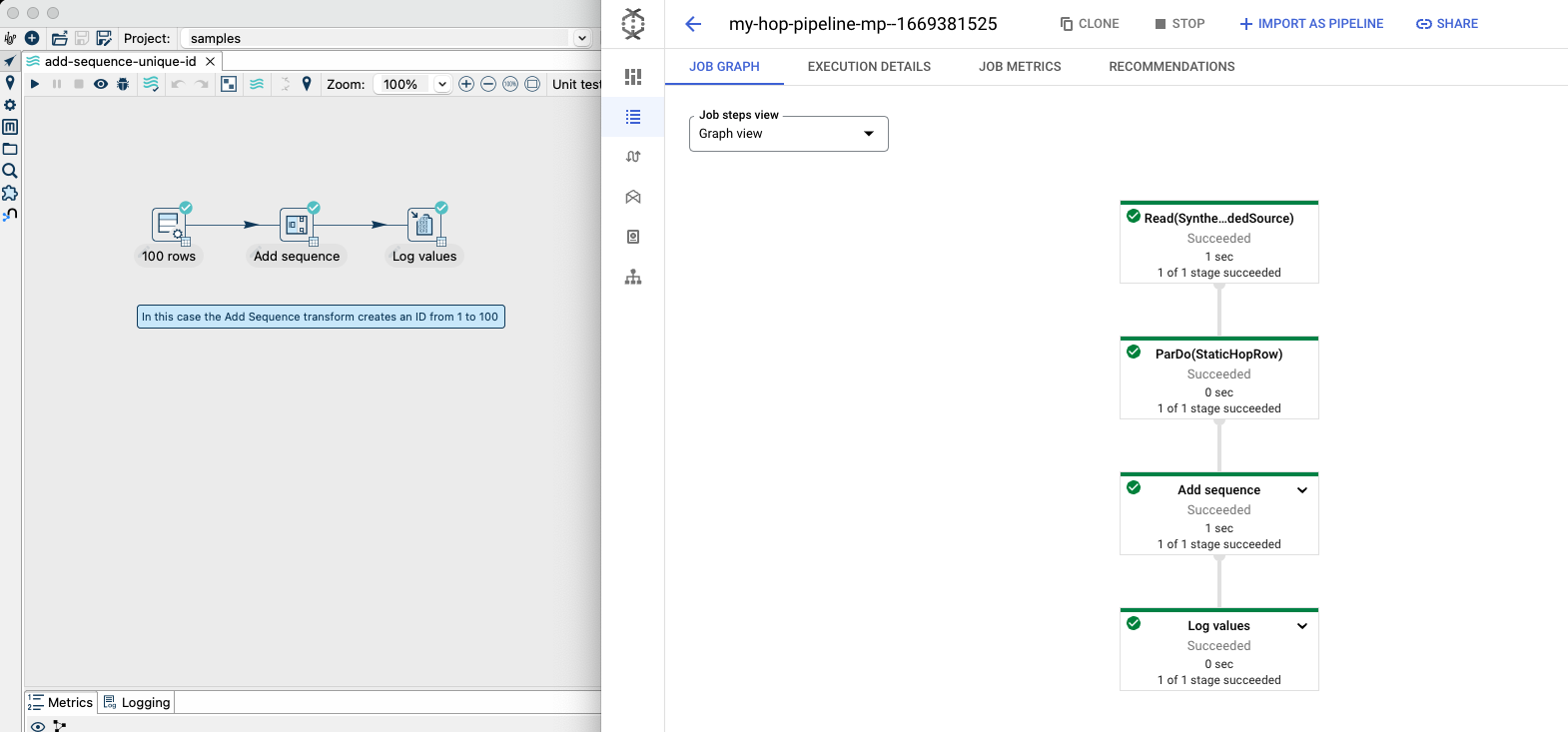
After pressing the create pipeline button you will be forwarded to a monitoring view, you can either wait for your schedule to trigger the pipeline or press the RUN button. In this dashboard, you will able to monitor the success rates of your pipeline and attach SLO levels to warn you when the pipeline no longer runs within certain thresholds.
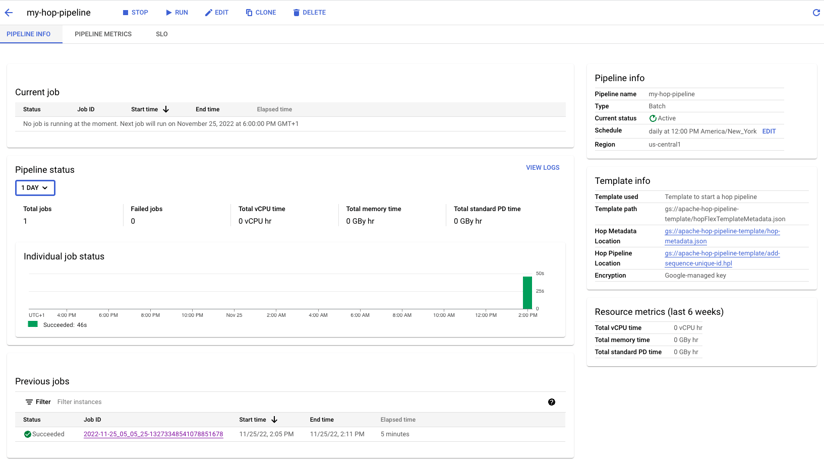
Lean With Data and the Apache Beam team at Google work closely together to provide seamless integration between the Google Cloud platform and Apache Hop. The addition to schedule and run pipelines directly on Google Cloud follows this philosophy. Now you don't have to worry about provisioning resources and are only billed for the compute time you use. This allows you to focus more on business problems and less on operational overhead.
As always, we'll be happy to help you get the most out of Apache Hop.
Get in touch if you'd like to discuss running your Apache Hop implementation in production, training or custom development.

Blog comments