The Apache Hop team released Apache Hop 2.3.0 yesterday.


The Apache Hop team released Apache Hop 2.3.0 yesterday.
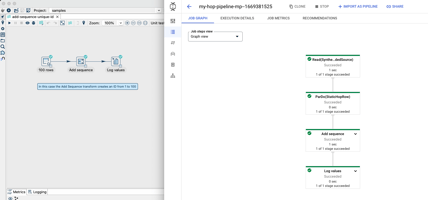
Google Cloud Dataflow is a Unified stream and batch data processing engine that...

The Apache Hop community just released Apache Hop 2.2.0, the fifth (!!) and final release of 2022,